신경망을 사용하기 위해서는 주어진 데이터에서 정답을 출력하는 파라미터를 찾아야 한다.
하지만 신경망의 파라미터의 갯수는 일일히 조작해서 얻기 힘들다.(Chatgpt 1750억개)
따라서 정답을 출력하는 모델의 파라미터를 효과적으로 근사시키는 알고리즘이 필요하다.
이러한 목적을 위해 보통 Gradient Descent라고 불리는 근사 기법을 사용한다.
문제 정의
주어진 데이터에 대한 함수를 f(x) 라고 하자. 이 때 x 는 신경망의 파라미터다.
이 함수는 신경망 x가 모든 데이터의 정답을 맞추면 0, 오답의 수가 늘어날수록 점점 커지도록 설계되었다고 가정한다.
이러한 함수의 예시는 모든 데이터에 대해 (Model(input)-label)^2의 합이 있다.
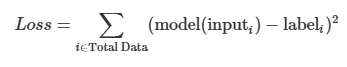
이때 적절한 모델 파라미터 x를 구하기 위해 일일히 대입해 보는것은 매우 비효율적이다. 따라서 gradient descent라고 불리는 방법을 사용한다.
Gradient Descent
파라미터가 1개 일때 다음과 같다.

우리는 Minima, 즉 미분값이 0인 평평한 지점의 파라미터를 구하기를 원한다. 따라서 미분했을때 0과의 차이, 즉 미분값 자체를 오차로 생각할 수 있다. 따라서 반복적으로 현재 파라미터에서 오차를 빼면, local minima를 구할 수 있다.
파라미터가 1개 보다 많을때도 미분값(그래디언트)을 계속 빼서 파라미터를 업데이트한다.

논의
Gradient descent 방법은 언뜻 보기에 2가지 문제가 있어 보인다.
1) 항상 모델이 minima로 수렴하는지
2)수렴한 Local minima가 좋은(현실에서 사용할 수 있는) minima인지
현재 2번은 연구가 더 필요하지만,현실에서 적용했을 때 잘 작동하는 것으로 보인다. 최근 논문은 grdient descent가 가진 특징 때문에 일반화가 잘 되는 minima로 학습된다고 주장하기도 한다. 하지만 함수의 Convexness에 대한 추가적인 가정이 없는 이상 Global minima로 수렴을 보장할 수는 없다.
1번은 현재 일반적인 상황에서 minima로 수렴시킬 수 있다는 것이 증명되어 있다. 이 내용은 추후 다룰 예정이다.
'연구 > 신경망 기초 이론' 카테고리의 다른 글
| Donsker and Varadhan’s variational formula (0) | 2025.04.24 |
|---|---|
| KL Divergence (0) | 2025.04.24 |
| Attribute 수집으로 해석한 신경망의 원리 (1) | 2025.04.19 |
| Stochastic Gradient Descent의 수렴성 (0) | 2025.04.19 |



